Leaky boat
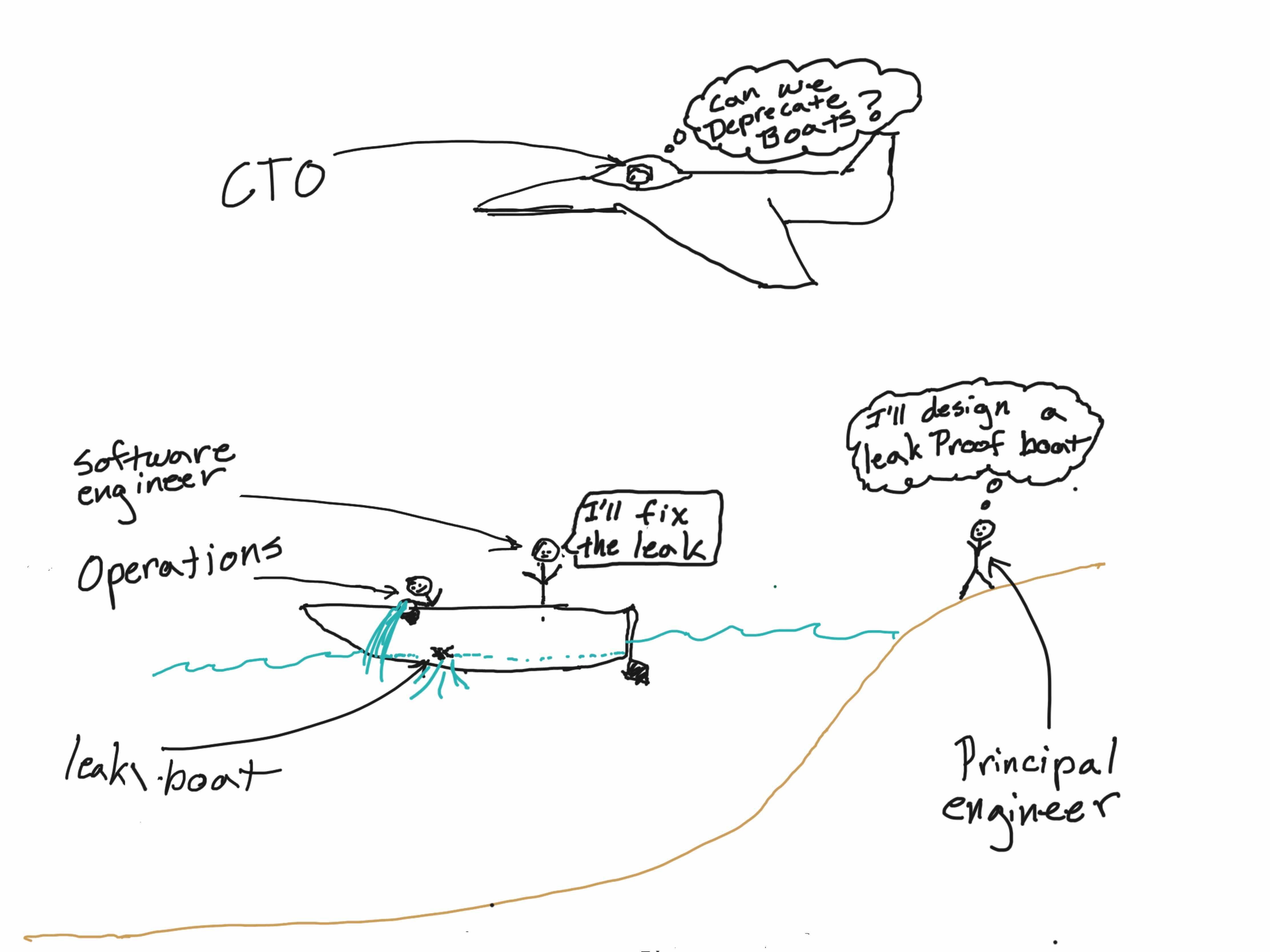
Software systems mirror a leaky boat in many ways. Most folks in the IT organization are trying to reduce and remove the risk that the boat will sink and all its occupants will meet their demise (software fails to meet objectives).
I imagine this analogy has been used before in other contexts, or perhaps even this exact one, but I’m a bit too lazy to go digging through the interwebs for prior work. So for the sake of this article, let’s just assume this is the first time you’ve heard such an analogy.
After engaging in some debates and discussions with colleagues about the proper engineering levels and organizational design, I felt inspired to share my thoughts on the subject openly and invite criticism of the viewpoint.
TL;DR
Technical organizations may want to consider risk assessment as a primary driver of the capital allocation process alongside project and team design. Given a proper risk profile one can design financial guardrails which can be used to inform organizational composition and reduce the impact of risk factors.
Deeper dive
Broadly speaking, IT professionals tend to fall into 1 of 4 groups as illustrated in my highly sophisticated stick figure diagram at the top of this article. To simplify things, I’m focusing on engineering, because it is the department I have the most experience with.
While there is a ton of nuance within a particular job role, I’m going to focus on how each group typically views risk and then suggest a portfolio based approach to managing that risk.
Group 1 - IT Operations
This group is largely concerned with keeping several software systems running and applying patches and updates. These folks tend to be concerned about risks that could impact the current revenue stream of the business. This group typically favors stability and tends to view risk on a system by system basis. They will often recommend a managed process for rolling out changes to production. This is where software engineers skilled in fixing the root cause can patch the software and reduce the overall workload for the operations team.
Group 2 - Software Engineers
Engineers are typically concerned with risk associated with feature production and release. Engineers at most organizations are paid to deliver features to end users based on weekly or monthly sprint cycles. Thus, a typical engineer is concerned with shipping features quickly and reliably while introducing as few defects as possible. Software engineers tend to view risk at the project level. This point of view can sometimes lead to local optimization at the expense of the entire system. For this reason organizations often employ principal engineers to help align engineering efforts across the organization.
Group 3 - Principal Engineers
Principal engineers typically try to mitigate risk associated with a system-wide inability to change over time. Because of the multi-system level focus, these folks typically focus on interface definition and reduction of technical debt as well as the creation of reusable abstractions and frameworks. A common blind spot many principal engineers have is knowing when to pivot to a new technology given the current one still functions. The decision isn’t obvious and can have long term consequences which is why it’s useful to have a big picture leader like a CTO to offer guidance.
Group 4 - CTO
These folks tend to view risks from two primary perspectives in my experience. The first is from a personnel point of view. If staff can’t or won’t support and work on a particular technology stack, the service that stack provides will fall behind competitor solutions. The second risk a CTO is typically charged with mitigating is the risk of business model disruption via technical superiority. This type of disruption typically happens on a long time scale and is often the result of organizations failing to assimilate new technologies into existing business processes which opens the door to nimble startups.
Why talk about risk at all ?
The reason I’m choosing to talk about risk in this article is to suggest that perhaps it makes sense to think about staffing an IT organization from a risk point of view in addition to the more typical project based point of view.
In modern portfolio management one decides on target asset allocation percentages based on a risk tolerance and then rebalances the asset allocation to match that risk tolerance. Labor is an asset that shares many commonalities with other non fungible assets, thus it makes sense to think about it in similar terms.
When we look at labor as an asset allocation problem where that allocation is weighted by risk, it gives us a flexible framework for introducing organizational change to meet our target allocation without getting into the details of every project or process the asset pool must support.
Example labor asset allocation
The following is a very basic example with nice round numbers to illustrate how a company might staff their organization based on this type of asset allocation strategy. A real analysis would take more time, have more risk factors and have numbers associated with real world conditions.
| factor 1 year | frequency | impact per incident | yearly cost |
|---|---|---|---|
| downtime incident | 6 | $100,000 | $600,000 |
| delayed feature | 2.5 | $200,000 | $500,000 |
| can’t change | 0.5 | $600,000 | $300,000 |
| disrupted | 0.05 | $5,000,000 | $250,000 |
Depending on how these numbers change from year to year a company might look to rebalance its labor pool. For example, if downtime became even more expensive and frequent, you’d likely want to increase staff levels to mitigate the impact.
Given our cost analysis we might end up with the following allocation.
| level | cost per staff member | staff count |
|---|---|---|
| IT Operations | $100,000 | 6 |
| Software Engineers | $125,000 | 4 |
| Principal Engineers | $150,000 | 2 |
| CTO | $250,000 | 1 |