Counting on dynamodb
Recently, some folks at my company Agero starting discussing strategies for pre-aggregating data that could be used for statistical compuation based on business metrics. Specifically, the question came up as to how we could maintain event counts.
Counting has a long history in the field of probability and statistics and is in many ways the most foundational form of data required for data science teams. A histogram is nothing more than bucketed counts and a probabilty distribution is just the continous version of the same thing. Maintaining counts is often a requirement of useful statistical computation. Thus, there is value in considering how one might count lots of things.
Having drank the serverless cool-aid a while ago, I’ve been using lambda and dynamodb heavily in recent years. I present the following as a possible solution to maintain counts in this type of environment:
Overview
First a rough architecture:

The infrastructure is pretty simple. We have a table that recieves our event data. This could be purchase data for a customer, ad impressions for a visitor or any other monotonic event source.
When an event arrives in our event table, dynamodb will automatically invoke our lambda function with the operation type “INSERT” and the payload representing the data that was placed into the event table. Based on this event data we construct a “PutItem” operation to upsert into our count table. For our use case we wanted to know, “how many jobs have been placed for a specific customer in the last 24 hours”.
For this demo I decided that minute level precision was close enough, but one could extend this solution to any level of precision. Really it comes down to how much extra one is willing to pay for additional decimal places of precision. There are trade-offs with any architecture and this architecture trades off a small bit of precision for a huge speed improvement on large datasets. Similarly there are tradeoffs in precision and cost in the real world. For example, one might use a tape measure for carpentry but a micrometer for machining.
Given we require minute level precision, we bucket all counts by both hour and minute. To illustrate why, consider the following:
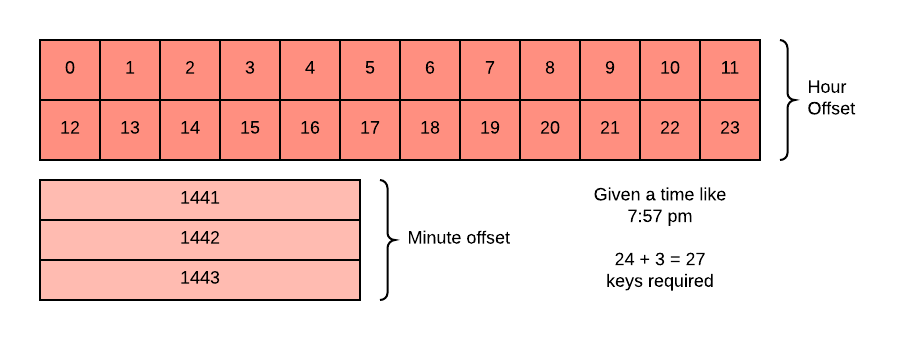
Given this diagram, the problem we are solving for with different levels of granularity becomes clear. When we move to the next hour in our series, we don’t have a full hour of data. Thus, we need to look back at the historical minutes and fill them in appropriately. This design means that our code will have to fetch between [24,24 + 59] dynamodb keys for every count we wish to calculate. The upper bound of 83 keys helps make our system performance more stable than if we had to make calculations based on 0..n number of events. 83 is also a good number as it can be queried without pagination from dynamodb.
The requirement to query up to 83 keys means that if we have very few events per 24 hour period the advantage of pre-aggregating goes away and we likely wouldn’t need to pre-aggregate at all. Thus, this type of counting is best used when we have a relatively high volume of event data coming in.
Implementation Details
This article is not about counting and aggregating generally. It’s intended to help folks aggregate and count things on dynamodb specifically. In this section I’ll dive into some of the techy details. I’m using dynamodb here but this same system could be used on any key value datastore that supports similar operations (Cassandra?).
The first thing we need to do is set up the infrastructure as illustrated in the Architecture diagram above. We use cloudformation to do that. It should be clear that this is creating two tables and one lambda function. The lambda function holds the code for translating events into counts.
Infrastructure
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
ProcessDynamoDBStream:
Type: AWS::Serverless::Function
Properties:
Handler: handle.handler
Runtime: python3.7
Policies:
- AmazonDynamoDBFullAccess
- AWSLambdaDynamoDBExecutionRole
CodeUri: ./streamHandler
Events:
Stream:
Type: DynamoDB
Properties:
Stream: !GetAtt DynamoDBTableEvents.StreamArn
BatchSize: 10
StartingPosition: TRIM_HORIZON
DynamoDBTableEvents:
Type: AWS::DynamoDB::Table
Properties:
TableName: 'event-counter-demo-events-table'
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
StreamSpecification:
StreamViewType: NEW_IMAGE
DynamoDBTableCounts:
Type: AWS::DynamoDB::Table
Properties:
TableName: 'event-counter-demo-counts-table'
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 30
WriteCapacityUnits: 30Code
# this is your lambda code handler.py
import boto3
table_name = 'event-counter-demo-counts-table'
dbclient = boto3.resource('dynamodb')
table = dbclient.Table(table_name)
# All timestamps are in milliseconds. These constants make it easy
# to convert units for bucketing
MILLISECONDS_IN_AN_HOUR = 3600000
MILLISECONDS_IN_A_MINUTE= 60000
MILLISECONDS_IN_A_SECOND= 1000
def handler(event, context):
for record in event['Records']:
if not record['eventName'] == 'INSERT':
next
dynamodata = record['dynamodb']['NewImage']
# helps us store multiple counters in one table
counterKeyPrefix = dynamodata['counterKeyPrefix']['S']
# this helps us set the ttl based on how long we want the
# count to remain valid. Different counters may have different requirements
retention = int(dynamodata['retention']['N'])
# snap the event time to the following buckets
milliseconds = int(dynamodata["insertUtcTime"]['N'])
hours = int(milliseconds / MILLISECONDS_IN_AN_HOUR)
minutes = int(milliseconds / MILLISECONDS_IN_A_MINUTE)
seconds = int(milliseconds / MILLISECONDS_IN_A_SECOND)
hourkey = "%s_hour_%s" % (counterKeyPrefix, hours)
minutekey = "%s_minute_%s" % (counterKeyPrefix, minutes)
# The magic of upserts. If we have no value set it to 1 otherwise increment.
# also given Null ttl, set that so we can expire the key automatically and avoid
# filling our table with un-used data.
update_args = {
'Key': {
'id': hourkey
},
'UpdateExpression': 'SET #count = if_not_exists(#count, :defaultval) + :val, #ttl = if_not_exists(#ttl, :ttl)',
'ExpressionAttributeValues': {
':val': 1,
':defaultval': 0,
':ttl': seconds + retention
},
'ExpressionAttributeNames': {
'#ttl': 'ttl',
'#count': 'count'
},
'ReturnValues': 'UPDATED_NEW'
}
# update the hour key
resp = table.update_item(**update_args)
# update the minute key
update_args['Key'] = { 'id': minutekey }
resp = table.update_item(**update_args)
print(resp)Now that you have code and infrastructure in place you can generate some event data and see the result.
# mockdata.py
import boto3
import uuid
import time
import datetime
from random import randint
event_table_name = 'event-counter-demo-events-table'
session = boto3.session.Session(profile_name='default')
dbclient = session.resource('dynamodb')
table = dbclient.Table(event_table_name)
start_hour = 1
end_hour = 37 # in real life there is no end...
TTL_FUTURE = 90000 # 25 hours in seconds
MILLISECONDS_IN_AN_HOUR = 3600000
# we want time in milliseconds
second, milli = str(time.time()).split('.')
if len(milli) >= 4:
milli = milli[0:4]
else:
milli = milli.zfill(4)
string_time = "%s%s" % (second, milli)
start_timestamp = int(string_time)
# create a bunch of random data for a 37 hour time period
for current_hour in range(start_hour, end_hour):
for times in range(0, randint(20, 100)):
simulated_insert_time = start_timestamp + randint(0, MILLISECONDS_IN_AN_HOUR-1)
print(simulated_insert_time)
# simulates 3 counters where we are counting per customer
provider_id = str(randint(1, 3))
counterKeyPrefix = "job_event_provider_id_%s" % provider_id
example_event = {
'id': str(uuid.uuid4()),
'insertUtcTime': simulated_insert_time,
'counterKeyPrefix': counterKeyPrefix,
'retention': TTL_FUTURE,
'providerId': provider_id,
'attribute1': 'data',
'attribute2': 'data',
'current_hour': current_hour
}
resp = table.put_item(Item=example_event)
print(resp)
start_timestamp = start_timestamp + MILLISECONDS_IN_AN_HOURLastly, you can query the counts database for a specific time range, aggregate the counts and do as you wish with that information.
# query.py
import boto3
FIRST_EVENT_TIME = # milliseconds for first event
PROVIDER_ID = 2
HOUR = int(FIRST_EVENT_TIME / 3600000) + 27
MINUTE = int(FIRST_EVENT_TIME / 60000) + (27 * 60)
MINUTE_MINUS_DAY = MINUTE - 1440
MILLISECONDS_REMAINING = FIRST_EVENT_TIME % 3600000
MINUTES_INTO_HOUR = int(((MILLISECONDS_REMAINING / 1000) / 60))
TRAILING_MINUTES = 60 - MINUTES_INTO_HOUR
session = boto3.session.Session(profile_name='default')
client = session.client('dynamodb')
# create a list of the hour keys we need
hour_keys = [ "job_event_provider_id_%s_hour_%s" % (PROVIDER_ID, HOUR - i) for i in range(0,24)]
# create a list of the minute keys we need
minutes_keys = [ "job_event_provider_id_%s_minute_%s" % (PROVIDER_ID, MINUTE_MINUS_DAY - i) for i in range(1, TRAILING_MINUTES)]
all_keys = hour_keys + minutes_keys
# format keys for dynamodb query
all_keys_query = [ { 'id': { 'S': k }} for k in all_keys]
print(all_keys_query)
resp = client.batch_get_item(
RequestItems={
'event-counter-demo-counts-table': {
'Keys': all_keys_query,
'AttributesToGet': [ 'count' ]
}
}
)
results = resp["Responses"]["event-counter-demo-counts-table"]
# aggregate all values client side
counts = [ int(result["count"]["N"]) for result in results]
total = sum(counts)
print(total)Fin
That’s all you really need for a basic dynamodb based counting system. There are many other ways you might construct a counting system and this article aims to offer but one approach. Questions and comments are always welcome.